NextCoder-32B
综合介绍
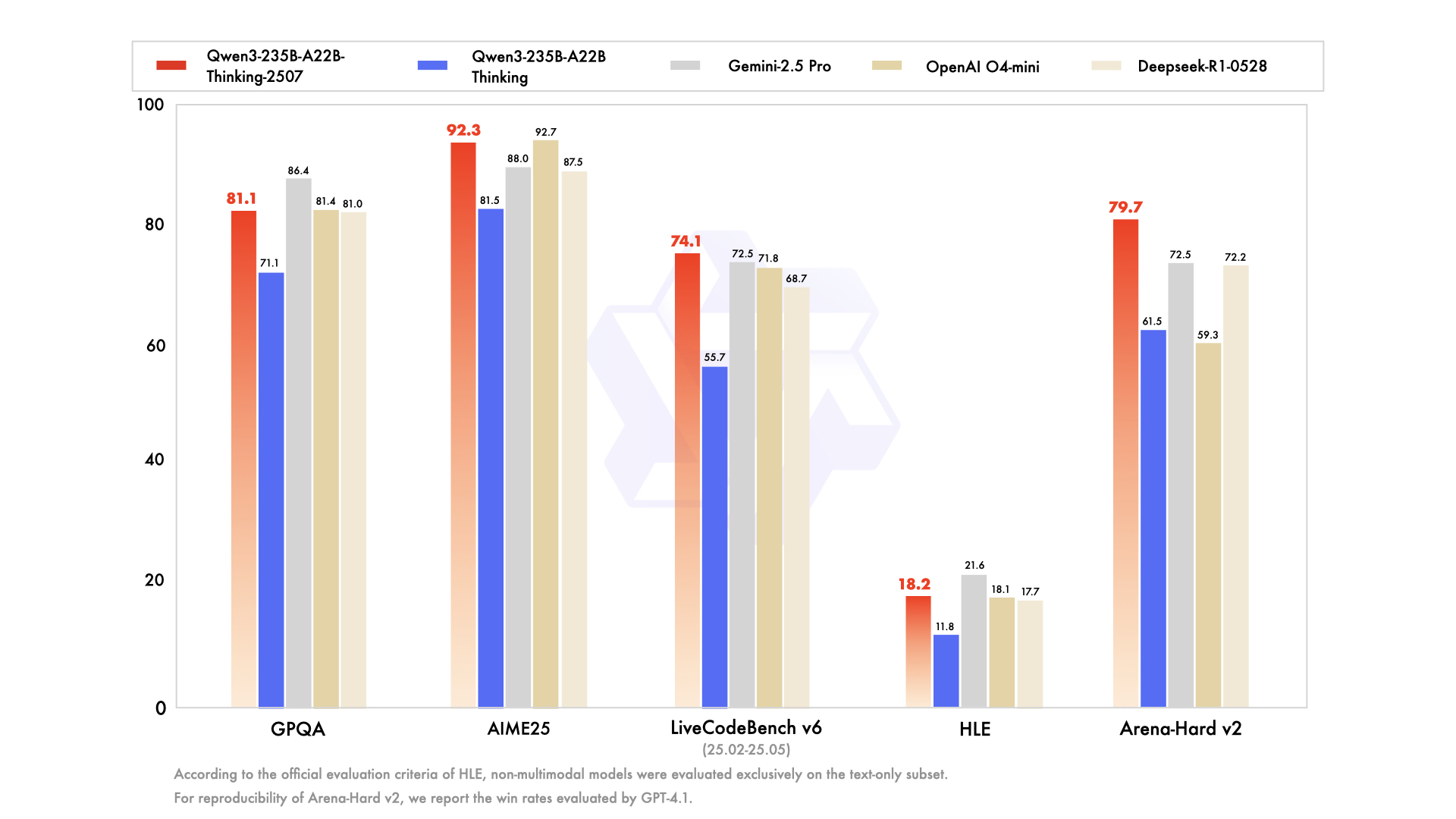
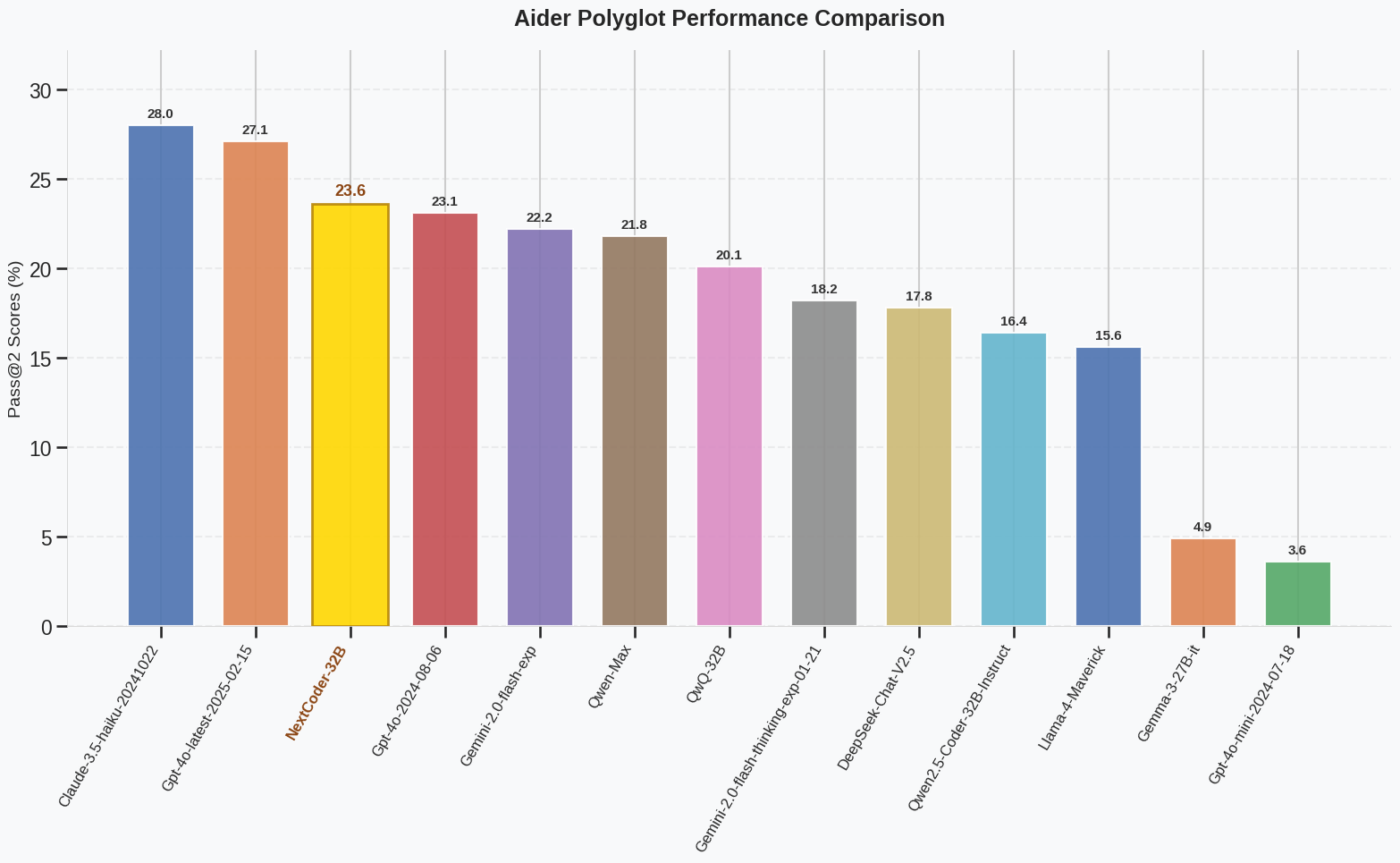
NextCoder-32B是由微软公司开发的一款专用于代码编辑的大型语言模型。 它基于Qwen2.5-Coder的变体进行构建,并采用了一种名为“选择性知识转移”(Selective Knowledge Transfer, SeleKT)的创新微调方法进行训练。 NextCoder系列模型提供了7B、14B和32B三种不同参数规模的版本,以适应不同开发者的需求。 此系列模型的核心优势在于其强大的代码编辑能力,在Aider-Polyglot等复杂代码编辑基准测试中,NextCoder-32B的表现能够媲美GPT-4o,性能相较于其基础模型提升了44%。 同时,得益于SeleKT微调方法,该模型在提升代码编辑能力的同时,没有损失通用的代码生成能力,并支持高达32,000个字符(32K tokens)的上下文长度。
功能列表
- 强大的代码编辑能力: 模型经过专门优化,擅长执行各种代码修改任务,例如修复错误、重构代码以及根据指令添加新功能。
- 多语言代码处理: 在Aider-Polyglot等多语言编程基准测试中表现出色,能够处理多种编程语言的代码。
- 保持通用代码生成能力: 采用创新的SeleKT训练方法,确保在提升代码编辑能力的同时,不会降低模型原有的代码生成水平。
- 长上下文支持: 支持最高32K的上下文长度,能够处理和理解包含大量代码的复杂文件和项目。
- 多种模型规模: 提供7B、14B和32B三种参数规模的模型,用户可以根据自己的硬件能力和需求选择合适的版本。
- 开源和可访问: 模型权重、训练数据集和相关工具均已开源,方便研究人员和开发者进行使用和二次开发。
- 兼容主流框架: 基于Qwen2.5架构,可以无缝地与最新版本的Hugging Face
transformers库集成使用。
使用帮助
NextCoder-32B模型的使用主要依赖于Hugging Face的transformers库。用户需要在本地或云端环境中配置好Python和PyTorch,并安装相应版本的库来加载和运行模型。
环境要求
首先,你需要一个安装了Python的环境。为了顺利运行模型,必须安装最新版本的transformers库。根据官方说明,低于4.37.0版本的transformers库会导致KeyError: 'qwen2'的错误,因此请务必升级。
你可以使用pip来安装或更新库:
pip install --upgrade transformers
pip install torch
快速上手
以下是一个基本的使用代码示例,展示了如何加载NextCoder-32B的分词器(tokenizer)和模型,并根据一个简单的指令生成代码。 这个示例的功能是修复一个有问题的除法函数。
- 导入所需库:首先,从
transformers库中导入AutoModelForCausalLM和AutoTokenizer。from transformers import AutoModelForCausalLM, AutoTokenizer - 指定模型并加载:设置模型名称为
microsoft/NextCoder-32B。然后使用from_pretrained方法加载模型和分词器。为了优化内存使用和计算效率,建议在加载模型时设置torch_dtype="auto"让其自动选择最佳的数据类型(如bfloat16),并使用device_map="auto"让库自动将模型分配到可用的硬件上(如GPU)。model_name = "microsoft/NextCoder-32B" # 加载模型,自动分配到GPU(如果可用) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto", ) # 加载分词器 tokenizer = AutoTokenizer.from_pretrained(model_name) - 准备输入指令:模型的输入需要遵循特定的对话模板。你需要创建一个包含
role和content的字典列表。对于代码编辑任务,role通常是user,content则是你希望模型执行的任务描述和相关代码。# 修复一个函数,处理除法中的边缘情况 prompt = """Fix the following function that divides two numbers to handle all the edge cases: def divide(a, b) returm a/b """ messages = [ {"role": "user", "content": prompt} ] - 应用对话模板并进行分词:使用分词器的
apply_chat_template方法将你的指令格式化为模型可以理解的字符串。之后,将这个字符串输入分词器,转换为PyTorch张量(tensors),并移动到模型所在的设备上。# 应用聊天模板 text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) # 将文本分词并转换为PyTorch张量 model_inputs = tokenizer([text], return_tensors="pt").to(model.device) - 生成代码:调用模型的
generate方法来生成回复。你可以通过max_new_tokens参数来控制生成内容的最大长度。# 生成回复 generated_ids = model.generate( **model_inputs, max_new_tokens=1024 ) - 解码输出:生成的
generated_ids包含了输入的ID和新生成的ID。为了只得到模型的回应,需要从结果中去除输入部分的ID。然后使用分词器的batch_decode方法将ID转换回人类可读的文本。# 从输出中移除输入部分的token generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ] # 解码得到最终的文本回复 response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] # 打印结果 print(response)运行完成后,
response变量将包含模型修复后的代码和相关的解释。
应用场景
- 代码修复与调试开发者可以将有错误的代码片段或整个文件交给NextCoder,并提供错误信息或简单的修复指令。模型能够分析代码上下文,定位并修正语法错误、逻辑漏洞或运行时异常,极大地缩短了调试时间。
- 代码重构与优化对于需要优化的旧代码,开发者可以要求NextCoder进行重构。例如,可以指令模型“将这段代码的循环结构改写为更高效的列表推导式”或“将这个类的方法拆分,使其符合单一职责原则”。模型能够理解重构目标并生成结构更清晰、性能更好的代码。
- 根据自然语言指令生成或修改代码这是NextCoder的核心应用场景。开发者可以用自然语言描述一个功能需求,例如“在用户类中增加一个验证邮箱格式是否合法的方法”,模型会自动编写或修改相应的代码,支持快速迭代和原型开发。
- 学习与教育编程初学者可以利用NextCoder来学习。当遇到不理解的代码时,可以请求模型进行解释;当自己的代码出错时,可以查看模型提供的修复方案和理由,将其作为一个全天候的编程导师。
QA
- 问题:NextCoder-32B与其他代码模型(如GPT-4o)相比有何优势?答案:NextCoder-32B的主要优势在于其专门针对“代码编辑”任务进行了深度优化。在Aider和Aider Polyglot等复杂的代码编辑基准测试中,它的表现可以媲美甚至在某些方面超过GPT-4o等更通用的模型。 它通过一种名为SeleKT的特殊训练方法,在不牺牲通用代码生成能力的前提下,显著提升了修改和优化现有代码的能力。
- 问题:运行NextCoder-32B需要什么样的硬件配置?答案:NextCoder-32B是一个拥有325亿参数的大模型,直接运行它需要非常强大的硬件,通常是配备了大量显存(例如80GB)的高端服务器GPU。 对于普通用户,可以考虑使用云服务平台提供的推理接口,或者使用社区提供的量化版本(如GGUF),这些版本经过压缩,可以在消费级GPU或CPU上运行,但可能会有轻微的性能损失。
- 问题:NextCoder是否支持中文指令?答案:NextCoder-32B的基础模型是Qwen2.5,该系列模型本身具备较强的多语言能力,包括中文。虽然官方文档和示例主要使用英文,但模型理论上可以理解中文指令。实际效果可能取决于指令的复杂性和具体任务。
- 问题:使用NextCoder生成的代码是否安全?答案:官方文档特别提醒,模型可能生成有害或易受攻击的代码。因此,所有由模型生成的代码在部署到生产环境之前,都应经过人工的严格审查和安全测试,例如在沙箱环境中运行验证。